

Descubra qué es Ollama y cómo le permite ejecutar LLM como Llama 3 localmente, garantizando privacidad, agilidad y control.
En el escenario tecnológico actual, la inteligencia artificial (IA) y, en particular, los Modelos de Lenguaje Grandes (LLMs), como el ChatGPT, han revolucionado la forma en que interactuamos con la información. Sin embargo, muchas de ellas dependen de la nube, y es en este escenario que Ollama surge como una solución poderosa.
Para un gerente de TI, por ejemplo, la complejidad en la migración a la nube, los costos impredecibles y las preocupaciones sobre la seguridad de los datos son desafíos diarios. El Ollama atiende a estos dolores, ofreciendo una alternativa que valora la relación costo-beneficio, la facilidad de integración y, sobre todo, la seguridad de los datos.
Prepárate para saber un poco más sobre el Ollama y descubrir cómo puede transformar tu experiencia con IA, ofreciendo un nuevo nivel de autonomía y eficiencia. ¡Echa un vistazo!

O que é o Ollama e por que pode ser útil para você
O Ollama es una plataforma innovadora que simplifica drásticamente la ejecución de Modelos de Lenguaje Grandes (LLMs) en su máquina local.
Imagina tener la capacidad de interactuar con modelos avanzados como el Llama 3, Mistral o Gemma, sin la necesidad de una conexión constante a internet. Esta es la promesa de Ollama: empaquetar modelos de lenguaje, sus dependencias y configuraciones necesarias en un formato fácil de usar.
En su esencia, Ollama funciona como un runtime para LLMs. Esto significa que proporciona el entorno y las herramientas necesarias para que estos modelos complejos se ejecuten de manera eficiente en sistemas operativos como Linux, macOS y Windows.
Sin embargo, la gran idea de Ollama es abstraer la complejidad de configurar entornos de desarrollo, gestionar dependencias y optimizar el hardware para cada modelo específico. Ofrece un sistema de “paquetes” donde cada modelo viene preconfigurado y listo para usar, solo se necesita un comando para descargarlo y otro para comenzar a interactuar.
Este diseño enfocado en la simplicidad hace de Ollama un puente accesible entre los usuarios y el poder de los LLMs de código abierto, fomentando la innovación y la experimentación sin las barreras técnicas que existían antes.
Vantagens de executar modelos em sua máquina
Ejecutar LLMs localmente con Ollama trae una serie de beneficios que impactan directamente en la experiencia del usuario.
Privacidade aprimorada
Esta es, quizás, la mayor ventaja. Al procesar datos en su propia máquina, garantiza que la información sensible no salga de su entorno. Esto es crucial para empresas que manejan datos confidenciales o para usuarios que valoran la discreción en sus interacciones con la IA.
Para un gerente de TI, la seguridad de los datos es una prioridad, y Ollama ofrece una solución directa para mitigar los riesgos de fugas.
Velocidade e baixa latência
La comunicación con servidores remotos siempre introduce un retraso. Con Ollama, las interacciones con el modelo son casi instantáneas, ya que el procesamiento ocurre directamente en su hardware.
En general, esto es especialmente perceptible en tareas que requieren respuestas rápidas, como chatbots o asistentes de código. Después de todo, la agilidad es un factor clave para optimizar el flujo de trabajo y aumentar la productividad.
Controle total
Aquí, tú estás al mando y puedes elegir exactamente qué modelos quieres usar, cómo configurarlos y cuándo actualizarlos. No hay preocupaciones sobre interrupciones de servicio de terceros o cambios inesperados en las políticas de uso.
Custo-benefício
La dependencia de las APIs de la nube puede llevar a costos impredecibles, basados en el volumen de uso. Con Ollama, el costo es fijo y está asociado al hardware que ya posees.
Después de la inversión inicial, puedes utilizar los modelos de manera intensiva sin preocuparte por la factura mensual. Esto ofrece una relación costo-beneficio superior, especialmente para proyectos con uso de IA a gran escala.
Personalização e experimentação
Los desarrolladores pueden ajustar y experimentar con los modelos de manera más libre, probando diferentes parámetros e integrándolos en sus propias aplicaciones sin restricciones externas. Esto, a su vez, acelera el ciclo de innovación.
Acessibilidade offline
Una vez que el modelo se descarga, puedes usarlo incluso sin conexión a internet, lo que es ideal para trabajar en campo o en lugares con conectividad limitada.
La capacidad de mantener la IA local transforma la forma en que pensamos sobre seguridad y autonomía digital, convirtiendo a Ollama en una herramienta esencial para el futuro de la computación personal y corporativa.
Como o Ollama funciona
El Ollama fue diseñado para ser intuitivo y eficiente, abstrayendo gran parte de la complejidad técnica de ejecutar LLMs.
En su esencia, actúa como un servidor local que aloja y gestiona los modelos, permitiendo la interacción a través de diferentes interfaces. Este enfoque simplifica el proceso de uso de LLMs para desarrolladores y entusiastas.
Ambiente isolado com modelos, pesos e dependências pré-configuradas
La magia de Ollama reside en su sistema de “modelos” empaquetados. Cada modelo que descargas (como llama3, mistral, etc.) viene como un paquete autocontenido, que incluye no solo los “pesos” del modelo (los datos que el modelo usa para generar respuestas), sino también todas las dependencias de software necesarias para su funcionamiento.
Con esta mecánica, crea un entorno aislado para cada modelo, evitando conflictos de versión y simplificando la instalación. Cuando ejecutas un comando para ejecutar un modelo, el Ollama:
- Verifica si el modelo ya está en tu sistema;
- Si no está, lo descarga de su repositorio central;
- Carga el modelo en la memoria, optimizándolo para tu hardware (CPU y/o GPU);
- Expone una interfaz para que puedas enviar prompts y recibir respuestas.
Este sistema de empaquetado asegura que la experiencia sea consistente, independientemente del modelo o del sistema operativo que estés utilizando. Además, hace que la instalación de nuevos modelos sea tan simple como teclear un comando.
Interface de linha de comando (CLI): comandos essenciais
La principal forma de interacción con Ollama es a través de su poderosa Interfaz de Línea de Comandos (CLI). Con algunos comandos simples, puedes descargar modelos, iniciar sesiones de chat y gestionar tus LLMs.
Aquí están algunos comandos esenciales:
- ollama pull <nombre_del_modelo>: descarga un modelo específico para tu sistema. Por ejemplo, ollama pull llama3;
- ollama run <nombre_del_modelo>: inicia una sesión interactiva con el modelo. Puedes empezar a escribir tus preguntas y el modelo responderá. Ejemplo: ollama run mistral. Para salir, escribe /bye;
- lista de ollama: muestra todos los modelos que has descargado e instalado en tu máquina;
- llama rm <nombre_del_modelo>: elimina un modelo de tu sistema, liberando espacio en disco.
- ollama serve: inicia el servidor Ollama en segundo plano, lo que es necesario para que otras aplicaciones (como GUIs o APIs) puedan conectarse a él.
CLI de Ollama es una herramienta robusta para aquellos que buscan control y automatización, permitiendo una fácil integración en scripts y flujos de trabajo.
Interface gráfica (GUI) e experiências mais amigáveis
Aunque la CLI sea poderosa, no todos los usuarios se sienten cómodos con ella. Afortunadamente, la comunidad Ollama y los desarrolladores independientes han creado Interfaces Gráficas de Usuario (GUIs) que hacen la interacción con los LLMs aún más amigable.
Estas GUIs generalmente ofrecen:
- Chatbots intuitivos: similares al ChatGPT, con un campo de texto para escribir preguntas y un área para las respuestas del modelo;
- Gestión de modelos: botones y menús para descargar, eliminar y seleccionar modelos sin utilizar la línea de comandos;
- Configuraciones avanzadas: opciones para ajustar parámetros del modelo (como temperatura y longitud de la respuesta) de manera visual;
- Integración con otras herramientas: algunas GUIs pueden ofrecer recursos adicionales, como la capacidad de crear “personas” para los modelos o integrarse con servicios de terceros.
Ejemplos de GUIs populares incluyen aplicaciones de escritorio independientes que se conectan al servidor Ollama en segundo plano. Son capaces de transformar la experiencia, haciendo el uso de LLMs locales accesible a un público mucho más amplio.
Para los desarrolladores, la capacidad de integrar Ollama con APIs significa que la lógica de negocio puede interactuar directamente con los modelos, abriendo un abanico de posibilidades para la creación de aplicaciones inteligentes y personalizadas.
Compatibilidade e requisitos técnicos
Para aprovechar al máximo el Ollama, es importante entender los requisitos de hardware y software. Aunque está diseñado para ser lo más accesible posible, algunos modelos pueden requerir recursos más robustos.
Plataformas suportadas: Linux, macOS, Windows
El Ollama se destaca por su amplia compatibilidad, estando disponible para los principales sistemas operativos del mercado:
- Linux: es una plataforma nativa y donde Ollama a menudo tiene el mejor rendimiento, especialmente en servidores y máquinas enfocadas en desarrollo;
- macOS: totalmente compatible, con optimizaciones para los chips Apple Silicon (M1, M2, M3), que ofrecen un excelente rendimiento para LLMs
- Windows: Ollama también puede ser instalado en Windows, permitiendo que los usuarios de este sistema operativo disfruten de los beneficios de los LLM locales.
Esta versatilidad garantiza que la mayoría de los usuarios pueda probar Ollama, independientemente del sistema que utilizan en sus ordenadores o portátiles.
Hardware recomendado: RAM, CPU e GPU
Los requisitos de hardware de Ollama dependen directamente del tamaño del modelo que planeas ejecutar. Los modelos de lenguaje son intensivos en recursos, principalmente en memoria RAM y, idealmente, en VRAM (memoria de la GPU).
- RAM (memoria principal): es el requisito más crítico. Los modelos más pequeños pueden requerir desde 8GB de RAM, pero modelos más complejos, como las versiones más grandes de Llama 3, pueden necesitar 16GB, 32GB o incluso más. Cuanta más RAM tengas, más grandes y complejos serán los modelos que podrás ejecutar de manera eficiente;
- CPU (procesador): un procesador moderno con múltiples núcleos es beneficioso, pero la GPU (si está disponible) generalmente realizará el trabajo más pesado;
- GPU (tarjeta de video): una GPU dedicada con mucha VRAM es lo que realmente acelera la ejecución de LLMs. Para una experiencia fluida, se recomiendan GPUs con al menos 8GB de VRAM, y lo mejor es tener 12GB o más para modelos más grandes. Las GPUs de NVIDIA con soporte para CUDA son las más optimizadas, pero Ollama también está ampliando el soporte para otras arquitecturas.
Para verificar los requisitos específicos de cada modelo, siempre es bueno consultar la página del modelo en el sitio oficial de Ollama o en la documentación de la comunidad.
Suporte a GPUs dedicadas e interfaces como Vulkan ou CUDA
El Ollama está diseñado para aprovechar al máximo el hardware disponible, y el soporte para GPUs dedicadas es una ventaja.
- CUDA (NVIDIA): si tienes una tarjeta de video NVIDIA, Ollama se integra perfectamente con la plataforma CUDA, que es el estándar de la industria para la computación de alto rendimiento en GPUs;
- Metal (Apple Silicon): para usuarios de Macs con chips M1, M2 o M3, Ollama utiliza la API Metal de Apple, optimizando la ejecución de los modelos para el hardware integrado y ofreciendo un rendimiento asombroso incluso sin una GPU dedicada tradicional;
- Vulkan: el soporte para Vulkan está en desarrollo y se está expandiendo, lo que permitirá a Ollama aprovechar las GPUs de otros fabricantes (como AMD e Intel) de manera más eficiente en el futuro.
La capacidad de aprovechar el poder de la GPU es lo que diferencia una experiencia fluida de una lenta al tratar con LLMs. Para un mayor beneficio, asegúrate de que tus controladores de video estén actualizados para garantizar la mejor compatibilidad y rendimiento con Ollama.
Modelos e usos comuns com Ollama
Ollama no es solo una plataforma para ejecutar LLMs; es un portal para una amplia biblioteca de modelos de lenguaje que se pueden utilizar en diversas aplicaciones. La flexibilidad de la herramienta permite que los usuarios y desarrolladores exploren el potencial de la IA de formas innovadoras y personalizadas.
Modelos disponíveis
Una de las mayores fortalezas de Ollama es el acceso facilitado a una diversidad creciente de modelos de lenguaje de vanguardia. La comunidad de IA de código abierto está en constante evolución, y Ollama actúa como un agregador, poniendo estos modelos a disposición para uso local. Algunos de los más populares incluyen:
- Llama 3: desarrollado por Meta, Llama 3 es uno de los modelos más avanzados y versátiles disponibles, con un excelente rendimiento en una variedad de tareas de lenguaje. Ollama ofrece diferentes tamaños de Llama 3, permitiendo elegir el equilibrio entre rendimiento y requisitos de hardware;
- Mistral: conocido por su eficiencia y alta calidad de respuesta, incluso en modelos más pequeños, Mistral se ha convertido en una opción popular para muchas aplicaciones.
- Gemma: lanzado por Google, Gemma es una familia de modelos ligeros y de código abierto, diseñados para ser eficientes e ideales para experimentación y uso local;
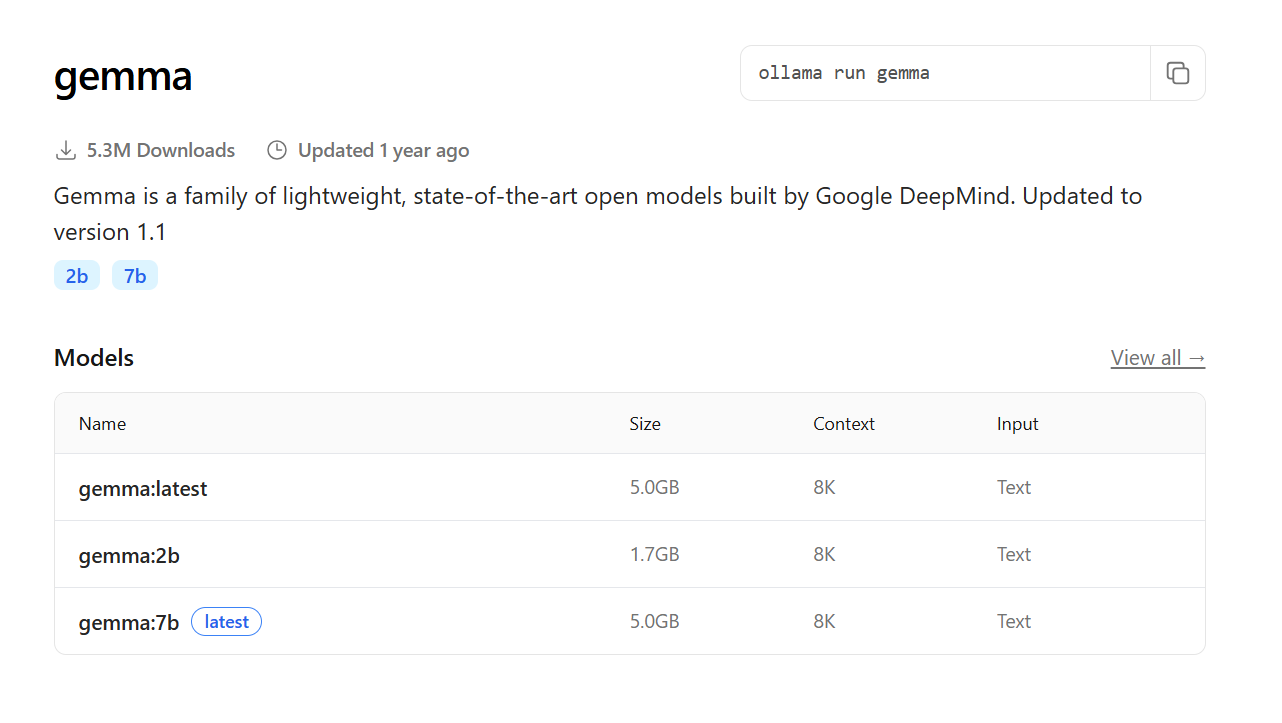
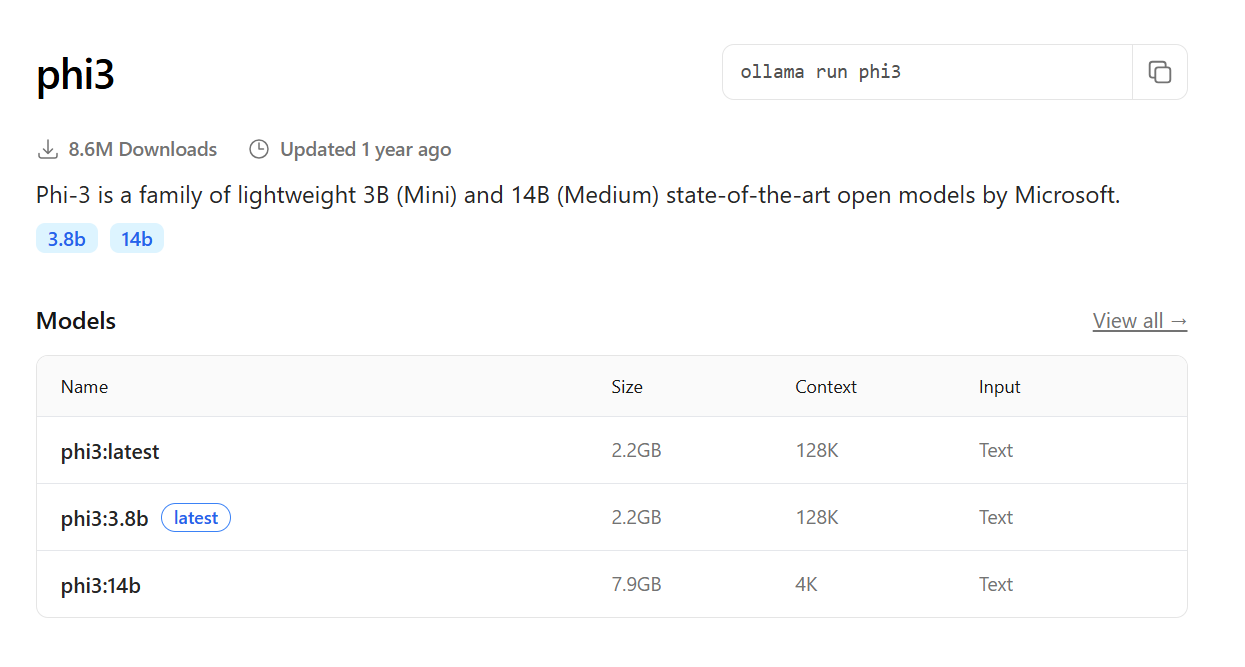
- Phi-3: otro modelo compacto, pero capaz, desarrollado por Microsoft, excelente para tareas que requieren respuestas rápidas con recursos limitados;
Desculpe, mas você não forneceu nenhum texto para traduzir. Por favor, forneça o texto que você gostaria que eu traduzisse.
- Codellama: una versión de Llama optimizada específicamente para la generación y comprensión de código, útil para desarrolladores.
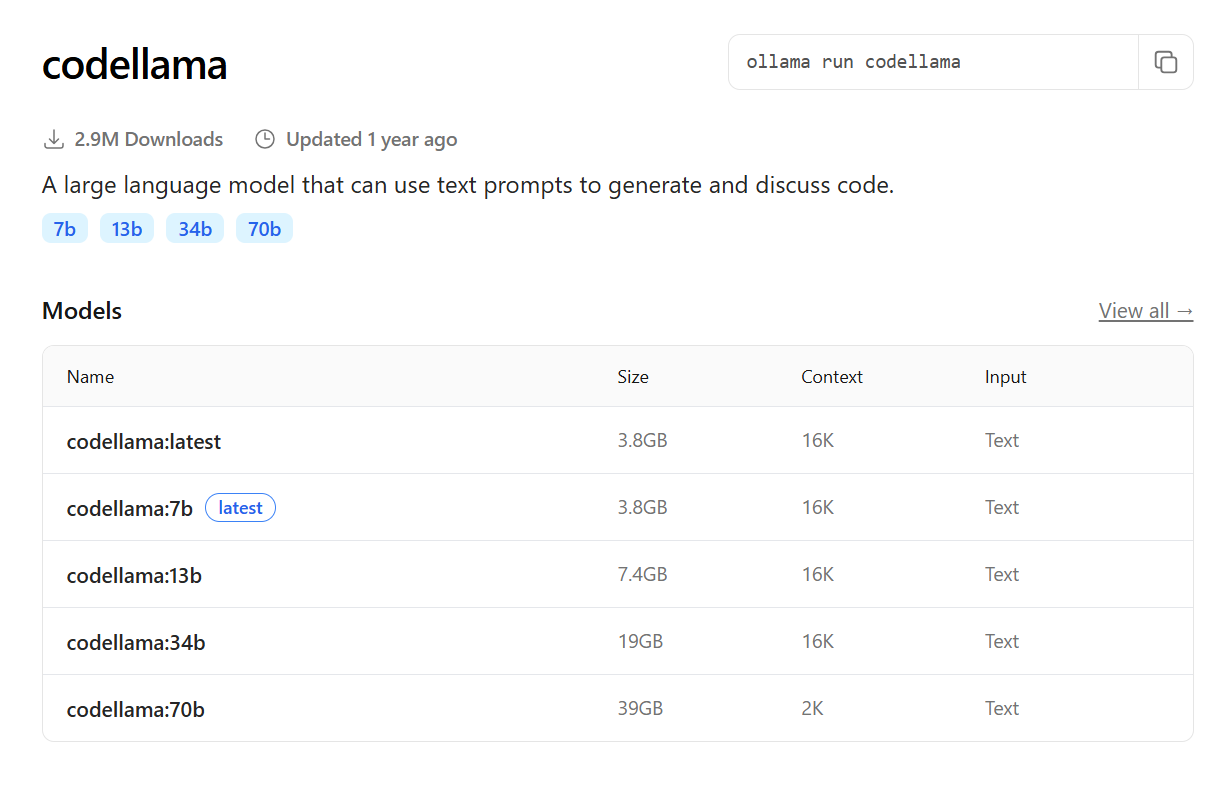
Además de estos, el repositorio de Ollama siempre se está actualizando con nuevos modelos y versiones optimizadas. Puedes explorar la lista completa de modelos disponibles en la página oficial de Ollama, donde cada modelo viene con una breve descripción y sus requisitos.
Aplicações típicas
La capacidad de ejecutar LLMs localmente abre un abanico de posibilidades para diversas aplicaciones. Por lo tanto, Ollama se convierte en una herramienta fundamental para:
- Chatbots y asistentes personales: crea tu propio chatbot con total privacidad, que puede responder a preguntas, generar texto creativo, resumir documentos e incluso ayudar en el brainstorming de ideas, todo sin que tus datos salgan de tu ordenador;
- Desarrollo y prototipado: los desarrolladores pueden usar Ollama para probar rápidamente nuevas ideas y funcionalidades basadas en LLMs, sin depender de APIs externas o incurrir en costos de nube. Es ideal para prototipar aplicaciones de IA, integrar modelos en software existente o crear herramientas personalizadas;
- Generación de contenido: use los modelos para ayudar en la escritura de artículos, correos electrónicos, guiones o cualquier tipo de contenido textual, acelerando el proceso creativo y garantizando la originalidad del material;
- Resumen y análisis de documentos: procesar documentos locales para extraer información importante, resumir textos largos o identificar patrones, todo con la garantía de que sus documentos permanecen confidenciales;
- Programación y automatización: con modelos como CodeLlama, los desarrolladores pueden generar código, refactorizar fragmentos, depurar problemas e incluso aprender nuevos lenguajes, todo asistido por un LLM local;
- Aprendizaje y experimentación: para estudiantes y entusiastas de IA, Ollama es una excelente plataforma para entender cómo funcionan los LLMs en la práctica, experimentar con diferentes modelos y explorar sus capacidades sin la complejidad de configuraciones avanzadas;
- Investigación y análisis de datos: en entornos donde la confidencialidad de los datos es primordial, Ollama permite el análisis de grandes volúmenes de texto, identificación de tendencias y soporte para la toma de decisiones, manteniendo todo dentro de los límites seguros de su infraestructura.
La versatilidad de Ollama lo convierte en una herramienta valiosa para cualquier persona interesada en aprovechar el poder de la inteligencia artificial de manera controlada y eficiente.
Do Ollama aos Agentes de IA: acessibilidade e resultados reais
Así como Ollama pone el poder de los Modelos de Lenguaje directamente en tus manos, HostGator también apuesta por soluciones que hacen la inteligencia artificial más accesible para cualquier emprendedor. Un ejemplo son los Agentes de IA de HostGator, que automatizan procesos como configurar dominios, ajustar correos electrónicos, crear contenidos y gestionar tareas del día a día digital.
Mientras que Ollama abre puertas para aquellos que desean explorar el universo de los LLMs de manera local y segura, los agentes de HostGator transforman esta tecnología en resultados prácticos para el crecimiento de negocios en línea.

Conclusão
El Ollama representa un hito importante en la democratización del acceso a los Modelos de Lenguaje Grandes, llevando el poder de la inteligencia artificial directamente a su computadora.
Al permitir la ejecución local de LLMs, garantiza privacidad, control y rendimiento superiores, ofreciendo una alternativa que a menudo supera las soluciones en la nube, además de proporcionar una buena relación costo-beneficio.
Con una instalación simplificada y una comunidad en constante expansión, Ollama hace más fácil y seguro explorar todo el potencial de la inteligencia artificial en la práctica.
Consultar también: